We are happy to share that our Render Pipeline Shaders (RPS) SDK is now available for open beta access!
What is the Render Pipeline Shaders (RPS) SDK?
The RPS SDK is a comprehensive and extensible Render Graph framework for graphics applications and engines using explicit APIs (such as DirectX® 12 and Vulkan®).
Background
Explicit graphics APIs are designed to reduce command recording overhead and unlock more CPU parallelism when driving the GPU. Due to their low-level and less stateful nature, tasks such as data dependency tracking and synchronization fall onto the shoulders of API users rather than the GPU driver.
Efficient transient memory management is another important aspect. Stateful, on-demand barrier generation and resource allocation often result in sub-optimal performance.
Render Graphs (also referred to as Frame Graphs or Task Graphs) have been proposed as an elegant and efficient solution to these problems. With an overview of the whole frame and the dependencies between individual passes (nodes), it is possible to schedule memory, barriers, and the workload more efficiently. However, in practice, implementing a render graph system from scratch is not a trivial task, and requires effort to keep it optimal as hardware, APIs, and content evolves. Porting effects and techniques between different render graph systems may also consume extra engineering time.
How the RPS SDK works
The RPS SDK intends to make Render Graphs more easily accessible and to provide a generally optimal barrier generator and (aliasing) memory scheduler. It has a compiler-like architecture, including a frontend used to specify resources and a node sequence, a runtime compiler which compiles the linear node sequence into a graph and schedules it, and a runtime backend that converts the scheduled render graph into graphics API commands.

RPS also tries to simplify Render Graph construction by extending HLSL with attributes and intrinsics to create a domain-specific language for render graph programming. This allows Render Graphs to be specified implicitly via a high-level, declarative programming model, allowing users to focus on the render pipeline logic rather than node configuration details. The access attributes and semantics specified at node declaration time are compiled offline into node signature metadata, which can be used at runtime for barrier generation, descriptor creation, and resource binding.
Copied!
// Node declarations
node Triangle([readwrite(rendertarget)] texture renderTarget : SV_Target0);
// Sample RPSL code
node Upscale ([readwrite(rendertarget)] texture dest : SV_Target0,
[readonly(ps)] texture source);
// Render Graph entry point
export void hello_rpsl([readonly(present)] texture backBuffer)
{
// Declare a transient texture resource
const ResourceDesc backBufferDesc = backBuffer.desc();
texture offscreen = create_tex2d(backBufferDesc.Format, uint(backBufferDesc.Width) / 2, uint(backBufferDesc.Height) / 2);
// Built-in clear node
clear(offscreen, float4(0.0, 0.2, 0.4, 1.0));
// Render to offscreen texture with user defined "Triangle" node
Triangle(offscreen);
// Blt offscreen to backbuffer with user defined "Upscale" node
Upscale(backBuffer, offscreen);
}
At runtime, applications can set variables and execute the RPSL code (or a user callback function which constructs the render graph with the C/C++ API), resulting in fully dynamic render graphs. This generates a list of active resources and nodes. Resources and per-node data can be cached efficiently between frames. The runtime compiler first goes through the lists, resolves node dependencies based on node signature and argument data and inserts transition nodes where necessary, generating a DAG which is passed along to the scheduler. The default scheduler schedules the DAG based on various considerations, such as barrier batching, memory usage & footprint, input node ordering, queue switch requirements, and so on. It also provides a set of flags for controlling the schedule behavior, such as forcing program order, prefer memory footprint saving (through aggressive aliasing), or prefer maximizing barrier batching. RPSL also supports a set of language constructs for fine-granularity controls.

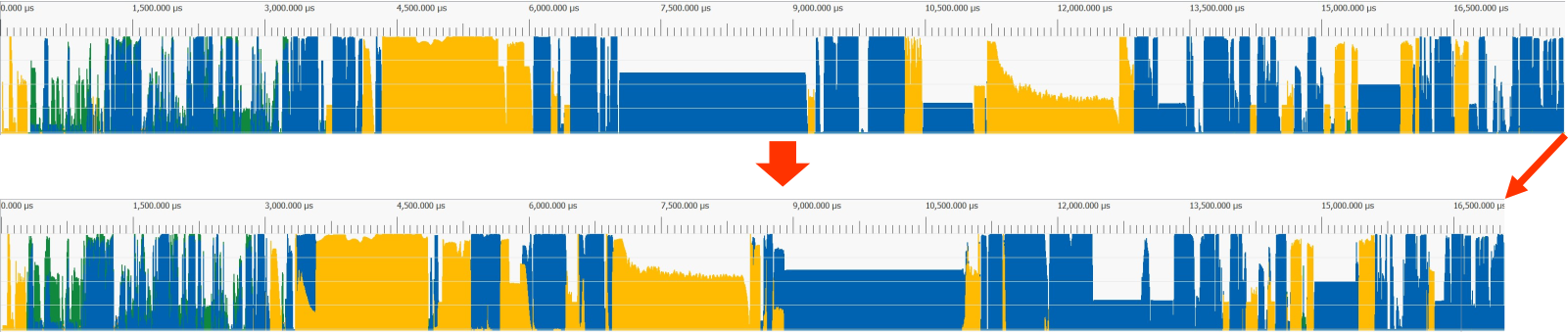
An example of an RPS-scheduled frame (bottom) compared to the original frame (top) from a real-world game trace:
An example of a scheduled memory layout, showing a heap space (Y axis) reused by aliased resources throughout the events in a frame (X axis):

Applications can bind node-implementation callback functions to render graph instances dynamically. The backend can handle the creation of API objects such as heaps, resources, and descriptors (as well as FrameBuffers and RenderPasses for Vulkan®). It can also bind resources when supported (currently it supports binding most of the non-shader resources), or setup basic render states such as the viewport and scissor rects. This reduces boilerplate code from the node callbacks.
RPS can be integrated into engines and applications progressively. With a bottom-up approach, it can be used to implement only a small module of the renderer, such as a multi-pass post-processing technique. With a top-down approach, it can be used as the skeleton of the frame, while each node can be a self-contained, multi-pass technique. RPS render graphs are also composable; for example, a render graph can be used as a node in another render graph.
Try it out with support!
Full source code is now available on GitHub, subject to an AMD evaluation license contained in LICENSE.rtf in the root of the repository.
To get support during this open beta, please get in touch with your AMD representative, or send a DM to @GPUOpen on Twitter or @GPUOpen@mastodon.gamedev.place. We might not be able to get back to you on Twitter or Mastodon during the open beta period, but your feedback is still very valuable, and we will read and try to respond to everyone.