





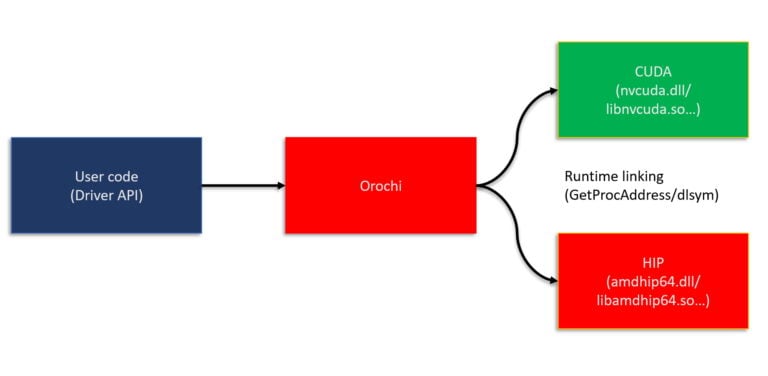
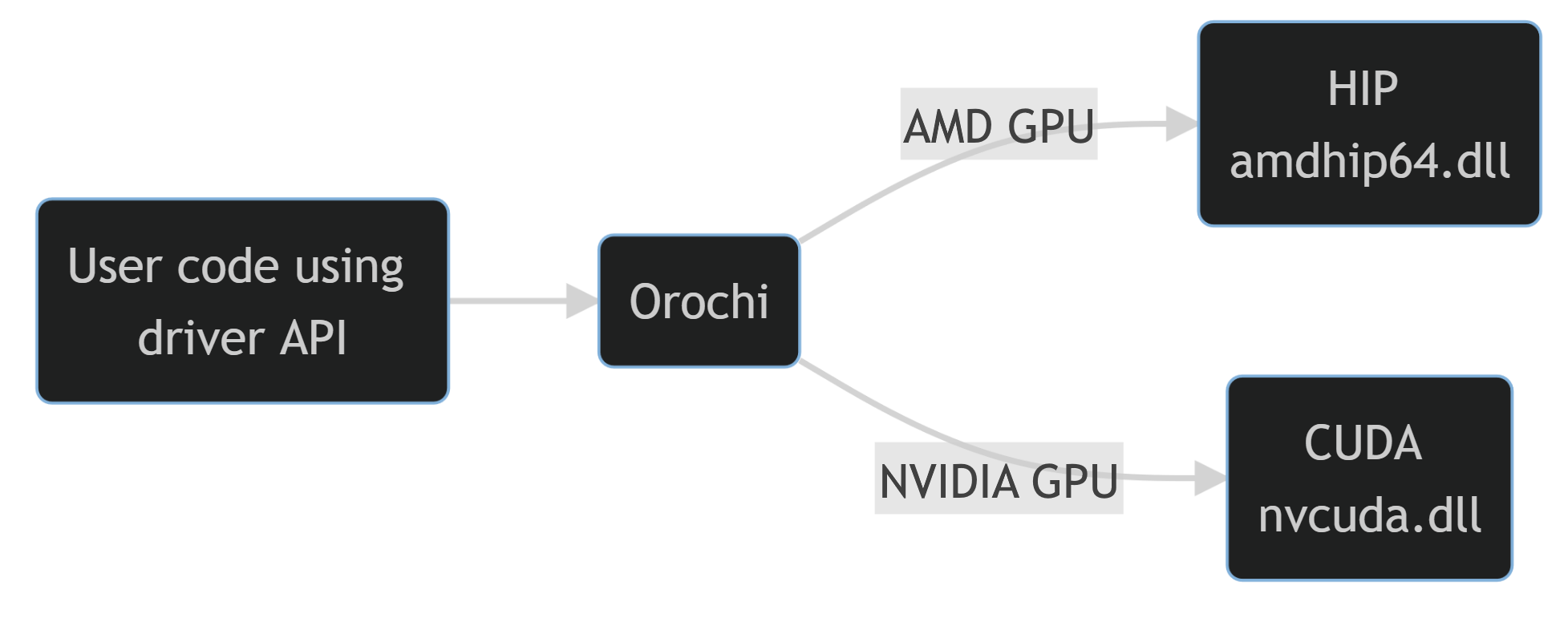
Orochi is a library that loads HIP and CUDA driver APIs dynamically at runtime, eliminating the overhead of maintaining separate backends.

Capsaicin is a Direct3D12 framework for real-time graphics research which implements the GI-1.0 technique and a reference path-tracer.

The Render Pipeline Shaders (RPS) SDK provides a framework for graphics engines to use Render Graphs with explicit APIs.

ADLX is a modern library designed to access features and functionality of AMD systems such as Display, 3D graphics, Performance Monitoring, GPU Tuning, and more.

Brotli-G is an open-source compression/decompression standard for digital assets (based on Brotli) that is compatible with GPU hardware.

HIP RT is a ray tracing library for HIP, making it easy to write ray tracing applications in HIP.

AMD Radeon™ ProRender is our fast, easy, and incredible physically-based rendering engine built on industry standards that enables accelerated rendering on virtually any GPU, any CPU, and any OS in over a dozen leading digital content creation and CAD applications.

Radeon™ Machine Learning (Radeon™ ML or RML) is an AMD SDK for high-performance deep learning inference on GPUs.

Harness the power of machine learning to enhance images with denoising, enabling your application to produce high quality images in a fraction of the time traditional denoising filters take.

The Advanced Media Framework SDK provides developers with optimal access to AMD GPUs for multimedia processing.

The D3D12 Memory Allocator (D3D12MA) is a C++ library that provides a simple and easy-to-integrate API to help you allocate memory for DirectX®12 buffers and textures.

The AMD Display Library (ADL) SDK is designed to access display driver functionality for AMD Radeon™ and AMD FirePro™ graphics cards.

The AMD GPU Services (AGS) library provides software developers with the ability to query AMD GPU software and hardware state information that is not normally available through standard operating systems or graphics APIs.